Spleeter 是什么

Spleeter是Deezer的音源分离库,用Python编写的预训练模型,使用Tensorflow。它使训练音源分离模型变得容易(假设你有一个孤立的音源数据集),并提供已经训练好的最先进的模型来执行各种类型的分离:
- 声乐(唱腔)/伴奏分离(2个音轨)
- 声乐/鼓/贝司/其他分离(4个音轨)
- 声乐/鼓/贝斯/钢琴/其他分离 (5个音轨)
2音轨和4音轨模型在 musdb 数据集上有很高的性能。Spleeter也非常快,因为它在GPU上运行时,可以将音频文件分离成4个音轨,比实时速度快100倍。
我们设计了Spleeter,所以你可以直接从命令行中使用它,也可以直接在你自己的 development pipeline 中作为一个Python库。它可以用pip安装或与Docker一起使用。
使用Spleeter的项目和软件
自从它被发布以来,有多个 fork 通过指导用户界面(GUI)或独立的免费或付费的网站展示Spleeter。
Spleeter 的预训练模型也已经被专业的音频软件所使用。这里有一个非详尽的列表:
- iZotope RX 8 中的音乐平衡功能
- SpectralLayers 7 中 Unmix 功能里的 SpectralLayers
- Acoustica 7 中的 Acon Digital
- 在 VirtualDJ 音源隔离功能中
- 在 NeuralMix 和 djayPRO 应用程序套件中的 Algoriddim
快速入门
想尝试一下,但不想安装任何东西?我们已经建了一个 Google Colab。
准备好进入它了吗?只需几行字,你就可以安装Spleeter,并从一个示例音频文件中分离出人声和伴奏部分。你首先需要安装 ffmpeg 和 libsndfile。它可以在大多数平台上使用Conda完成:
# install dependencies using conda
conda install -c conda-forge ffmpeg libsndfile
# install spleeter with pip
pip install spleeter
# download an example audio file (if you don't have wget, use another tool for downloading)
wget https://github.com/deezer/spleeter/raw/master/audio_example.mp3
# separate the example audio into two components
spleeter separate -p spleeter:2stems -o output audio_example.mp3
⚠️ 注意,我们不再推荐使用conda来安装spleeter。
⚠️ 苹果M1芯片有已知的问题,主要是由于TensorFlow的兼容性问题。在这些问题被修复之前,你可以使用这个变通办法。
你应该会在output/audio_example文件夹中得到两个分离的音频文件(vocals.wav和accompatiment.wav)。
关于详细的文档,请查看仓库的wiki
开发和测试
这个项目是用Poetry管理的,要运行测试套件,你可以执行以下一组命令:
# Clone spleeter repository
git clone https://github.com/Deezer/spleeter && cd spleeter
# Install poetry
pip install poetry
# Install spleeter dependencies
poetry install
# Run unit test suite
poetry run pytest tests/
疑难解答
Spleeter是一个复杂的软件,尽管我们不断努力改善和测试它,但你可能会遇到意想不到的问题。如果是这种情况,请先查看常见问题页面以及当前开放的问题列表。
Windows用户
似乎有时快捷键命令 spleeter 在Windows上不能正常工作。这是一个已知的问题,我们希望能很快解决。在此期间,在命令行中用 python -m spleeter separate 代替 spleeter separate ,它应该可以工作。
在线使用 Google Colab
打开 Colab ,保存副本,开始使用。
这里预先写好了项目的整个代码,点击“代码执行程序”-“全部运行”,将所有的代码都运行一下。
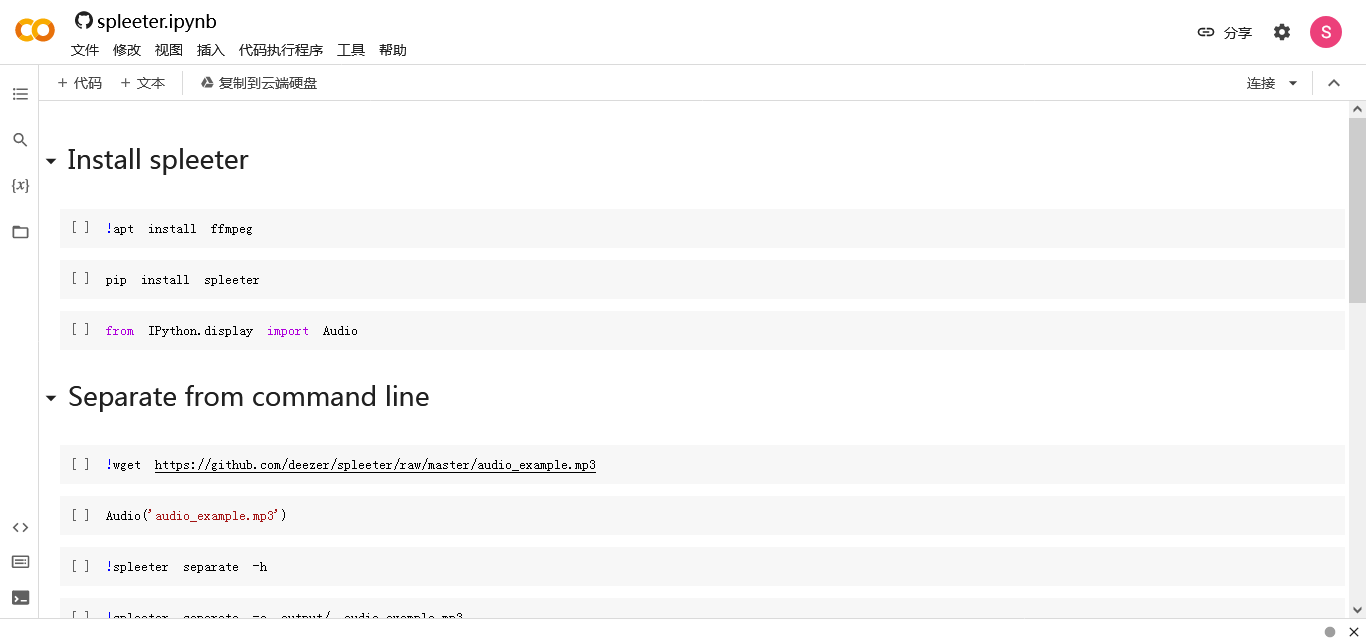
程序会自动运行,安装各种依赖、库文件,并将一个预设的audio_example.mp3 音频文件进行人声、伴奏分离。
我们试一下分离自己上传的音频文件,这里准备了一个叫 op-audio.mp3 的文件,点击左边的上传按钮即可将文件上传到云端。
/*装载 Google 云端硬盘*/
from google.colab import drive
drive.mount('/content/drive')
/*在右边新建一个代码块,照着上面的分离代码修改一下,再运行一遍。*/
spleeter separate -o output/ op-audio.mp3
注意这里不要改上面代码,不然——
!wget /content/op-audio.mp3
/content/op-audio.mp3: Scheme missing.
当然你也可以像示例一样分离存储在 github 仓库中的音频文件,像这样
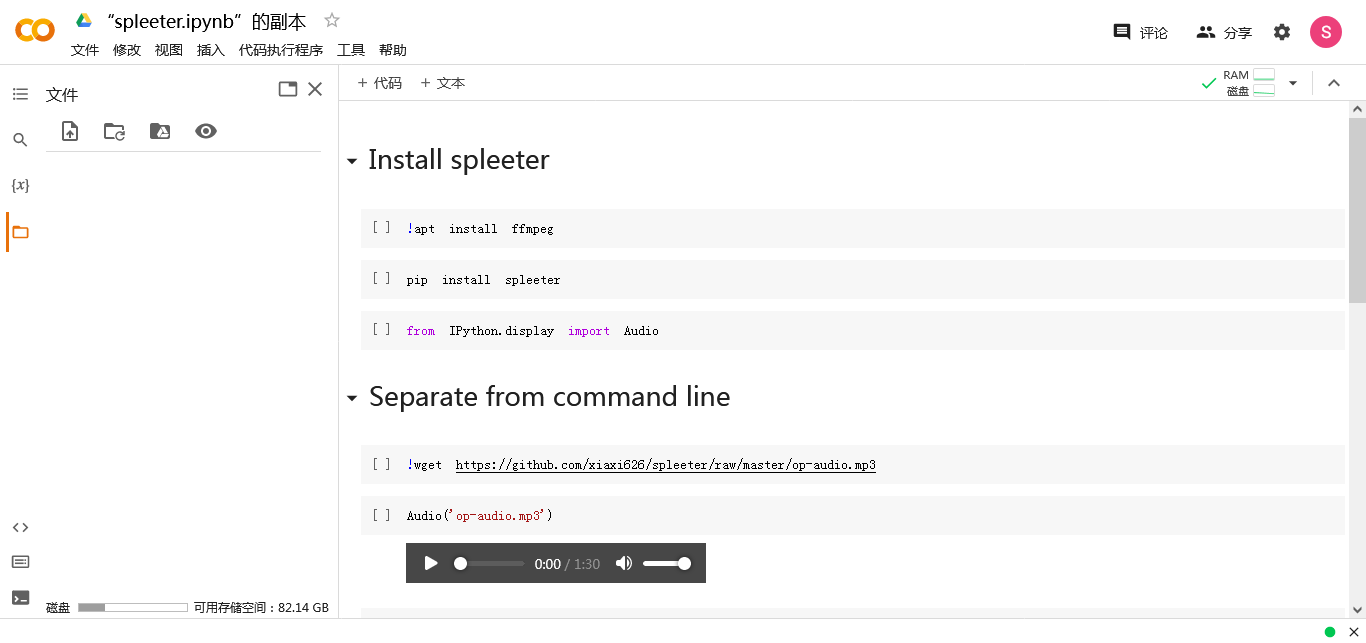
最后分离出来两个文件,accompaniment.wav为伴奏,vocals.wav为人声。
安装 spleeterGUI 图形界面软件
spleeterGUI 是基于 spleeter 进行深入开发的适用于 windows 平台的图形化界面软件。
下载地址:https://github.com/boy1dr/SpleeterGui
最新的安装程序可以从这里下载 https://makenweb.com/#spleetergui
不需要安装python或spleeter,这个应用程序包含一个预装了spleeter的便携式python版本。
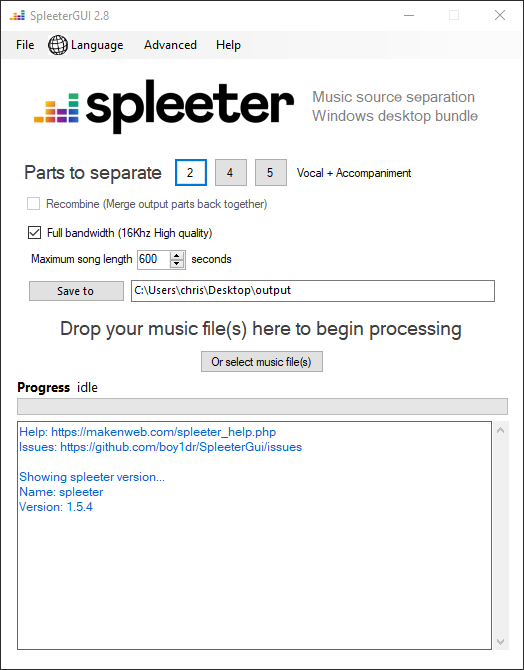
这个项目的目的是使Windows用户能够轻松地下载和运行Spleeter,而不需要使用命令行工具来完成。
支持的语言: 阿拉伯语、中文、英语、法语、印地语、意大利语、日语、俄语、西班牙语。
Intel Pentium & Celeron CPU不能运行spleeter
如果你运行的不是intel i5/7/9或Ryzen 5/7,或者不确定你的CPU是否支持AVX,请在尝试安装spleeter之前使用AVX检查工具(上文)。
打开软件后选择 parts to separate(分离声部,一般就是2),设置好文件保存路径(save to),选择需要分离的音频文件(支持多个音频文件),即可快速导出!
加载多个音频文件时,输出路径下会输出多个原文件名的文件夹,内含 accompaniment.wav 和 vocals.wav。
运行过程中遇到问题请前往 Github Issue 和 spleeter_help 搜索。
问题
httpx.ReadTimeout: The read operation timed out
Can't load save_path when it is None
解决方法
删除“…/SpleeterGUI/pretrained_models“文件夹中的模型文件夹(如“2stems”)。
下载“https://github.com/deezer/spleeter/releases“中“Spleeter public release“的文件,把它们解压到“pretrained_models“文件夹。